Building a Deep RL Model for Plasma Shape Control in Tokamaks
In the last post, we described NSFsim — our simulator of plasma in tokamaks. Now, we are excited to share the progress of our flagship project, which leverages NSFsim extensively. This project aims to develop a machine learning (ML) model to control plasma performance and shape using the magnetic system of a tokamak.
Over the past year, our ML team completed a full-cycle research, including the implementation of the environment, testing various approaches to model training, and deployment of the trained model as a novel plasma control algorithm to a fusion device.
Project Genesis and Inspiration
A fusion energy-producing reactor will confine a very high-density plasma for a long period of time. Such working regimes are relatively unexplored and known to have inherent instabilities. Conventional PID controllers for the tokamak magnetic system are a proven and long-existing solution. However, they require extensive manual adjustment and they can hardly handle high-density and high-confinement regimes effectively due to the dynamic and nonlinear nature of plasma behavior. Machine learning approaches, particularly reinforcement learning (RL), offer a superior alternative.
An ML-trained rather than explicitly programmed control algorithm can leverage complex patterns of plasma dynamics to ensure more precise control and stability. By continuously learning and optimizing, ML models can respond to real-time fluctuations and unforeseen events, ensuring the consistent and safe operation of fusion devices.
A reinforcement learning model consumes sensor data and outputs actuators’ actions. One of the important papers on the field is DeepMind’s work on the TCV. The paper provided a fair amount of details about model training, environment description, the algorithm used, neural networks’ sizes and topology, as well as the number of policy updates required to achieve decent results. However, direct reproduction of their results on a different device with its own magnetic system, power system and software (Plasma Control System — PCS) is far from straightforward.
At the moment when we initiated the project, our NSFsim was in its early stages. It could already simulate plasma, and we had the DIII-D tokamak preliminary configured in the simulator using publicly available data. A great mathematical model had been implemented, and the only thing it lacked to use it for RL was an API allowing the running of a simulated device as a Farama Foundation Gymnasium-compatible environment (formerly known as OpenAI Gym).
Tailoring the Environment
We have to say, there were a lot of issues with the environment in the beginning. The publicly available data allowed us to configure the positions of the coils and sensors by scaling drawings and figures from published papers [1–7] with a reasonable degree of accuracy, resulting in three discharges. We also obtained a snapshot of a single state from the middle of the flat-top phase of each discharge by solving an inverse problem to reconstruct the plasma shape. This provided us with an environment to run our RL algorithms and the target shape to control.
However (do you remember the “to some accuracy” part?), some of the states were so unstable that even slight modifications of the initial values, like moving a coil current off by 1e-3 Amps, could move the plasma by half the vacuum chamber width. Our physicists worked hard to adjust the initial states and provide stable enough settings to enable control. The ML engineers, for their part, invented more and more metrics to test the stability and separate cases when the state itself is not perfect or when the control model is just not good enough yet to control the plasma for 1 second.
Also, we went through several cycles to define the action space consistent with DIII-D. Although there was available data on the magnetic system (like the number of turns for each coil, their size, material, and position), it was not perfectly clear what speed of current change is achievable at each point of the state space.
Challenges in Reinforcement Learning
As it is common in RL projects, the algorithm did not perform perfectly out of the box. We spent considerable time fine-tuning the reward formula and algorithm hyperparams.
After some trials, we were thrilled to see the first stick-like chart. We achieved this with the PPO algorithm. The trained model was able to control the plasma shape for 0.2 seconds. Although insufficient for practical application, this marked significant progress.
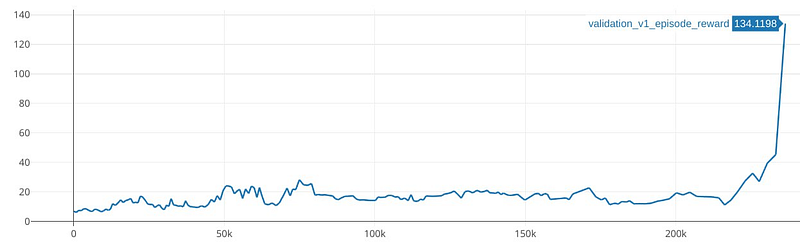
We recognize the limitations of on-policy algorithms like PPO, particularly their low sample efficiency. The above chart was a single training run for eight days straight.
Ultimately, we opted for the SAC (Soft Actor-Critic) algorithm and used 3-layer MLPs for both actor and critic. The reward is based on the plasma magnetic center’s distance to the target and plasma boundary’s distance to the target shape (calculated as the average distance of 32 points).
The reward formulas in DeepMind’s paper reflect the nature of RL with a huge amount of ad hoc engineering by trial and error rather than theoretically justified decisions. For example, they used different averaging functions (geometric mean and smoothmax) for different shapes. In our case, we also had to try several approaches and ended up with the smoothmax. In later phases of the project, we aim to implement more standardized solutions instead of relying on the techniques commonly used during the R&D stage. That will help formalize decision procedures, which are required in mission-critical applications.
The model needs some perspective on process dynamics in plasma. There are some choices to feed it with this information: for example, a frame stack using a recurrent model for the actor. In our case, we added to the observations derivatives of the values (simply differences between the current value and one on the previous iteration over the time increment).
Along with plasma simulation, you have to make some decisions on the control side. Initially we invoked the control mode with the same frequency as used by the physical simulation. One single tremendous control improvement occurred when we changed the time scale of decisions by the ML model from 0.1 ms to 1 ms. The hypothesis here is that you need to match control frequency with the speed of change in the environment state itself. So we implemented a repeat action env wrapper and asked the model only once per 10 low-level steps.
As a result, we were able to train a model that could control plasma for 1.5 seconds and push it to the target shape, even from a quite distant initial position. See the animation: blue points represent the plasma, and black points represent the target shape and position.
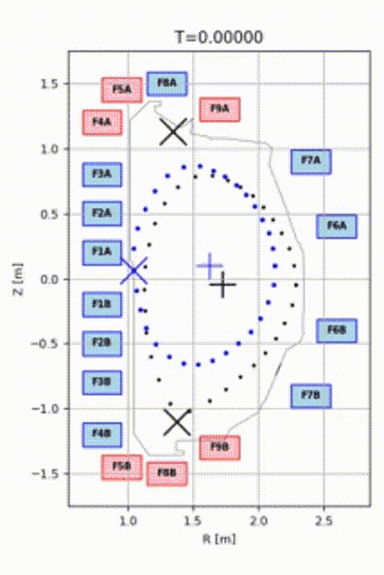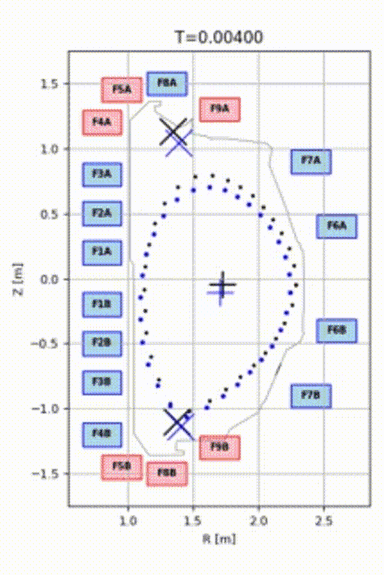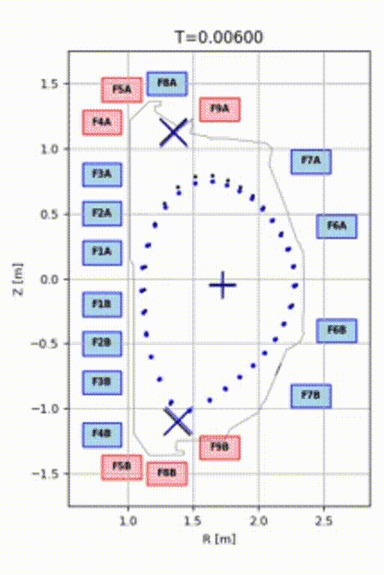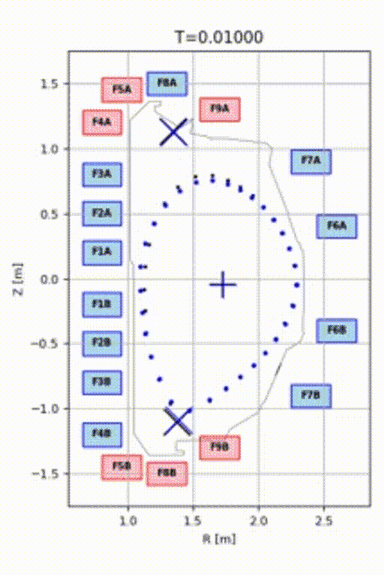
Model Robustness and Verification
After carefully nurturing your ML model in a simulated environment (in vitro :)), it’s time to take the next crucial step: testing its performance in the real world. This process, known as sim2real domain transfer, evaluates whether the model can effectively transition to real device conditions. Nature will always introduce additional effects that you cannot simulate. Effective sim-to-real relies not on a perfect simulation but on making your agent more robust.
But before we run an experiment on a device, we must try to transfer the control to another simulator. You can call it sim2sim transfer instead of sim2real. By the time our training metrics converged to a decent range, Next Step Fusion joined the DIII-D User program and got access to their own comprehensive simulation platform — GSevolve.
Despite its name, GSevolve is not only a Grad-Shafranv solver but also a simulation of the whole device, including the power system, sensors, etc. We did not need to wrap this simulator inside a trainable pipeline, only inference of our model is needed for testing. This approach doesn’t allow us to directly train the model on GSevolve, we just can see a collapsing plasma. However, if the plasma shape is controlled, the exercise demonstrates that the model really learned underlying physical and device fundamentals, not only the peculiarities of a certain simulator.
To achieve the sim2sim quality, we had to add noises to the environment. The noises have different natures:
- Noises in the initialization (the state on handover is not the same as in the reference configuration)
- Noises in actions (the action applied is not the same as requested by the model)
- Noises in measurements (sensors’ values are not exactly equal to the corresponding physical quantities)
After this modification of the training environment, we were able to reproduce the evaluation with GSevolve using the model trained with NSFsim.
In a simulated experiment, the ML agent controlled plasma for 1 second. The accuracy turned out to be lower than in our simulation but good enough for proof of concept. Additionally, it is important to mention that being a participant of the DIII-D User program allowed us to get access to experimental data and verify accuracy of NSFsim with a larger number and wider variety of the shots.
After plasma simulation was verified, we had some hard time tweaking parameters of the sensor system. Finally, the simulator was verified and updated the device configuration after the 2024 maintenance campaign.
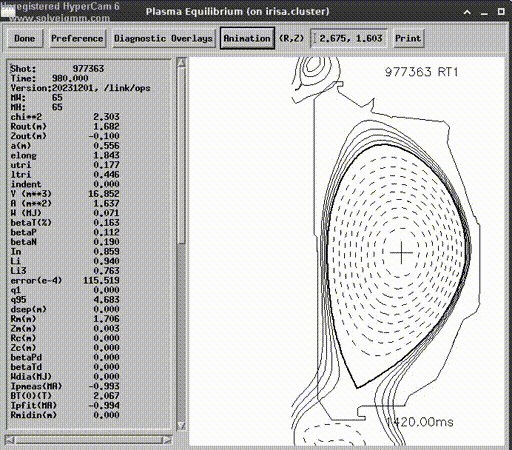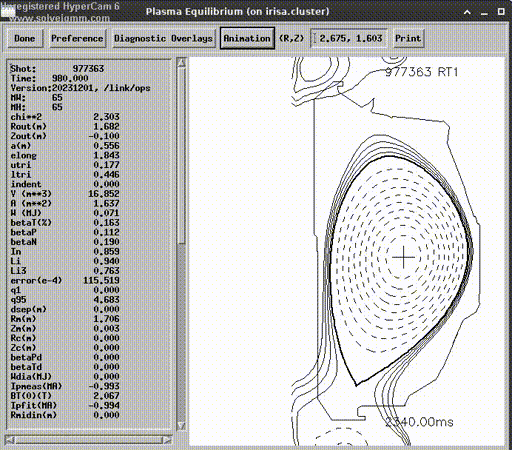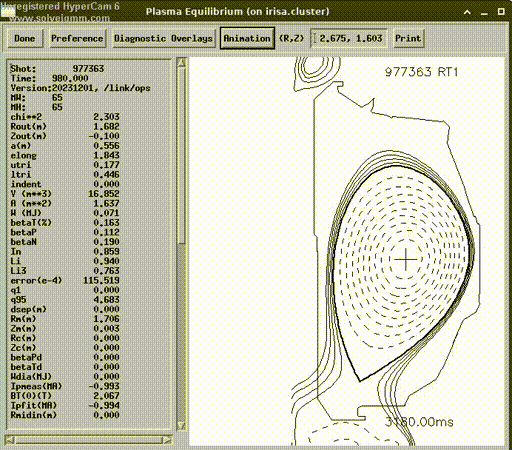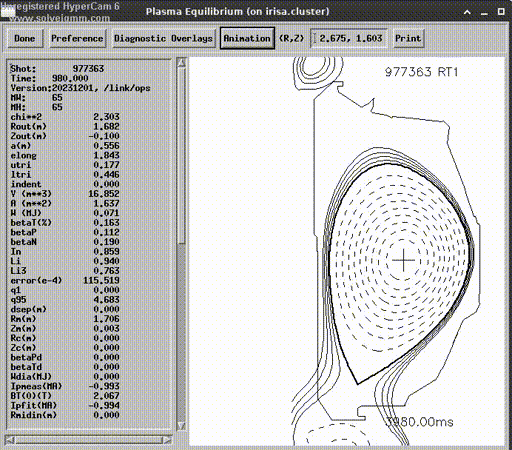
Lessons Learned
- Plasma is a turbulent medium: Although we (humanity) understand particle physics well, a lot of emergent phenomena cannot be modeled fast enough to make an informed, physically justified decision in real time. This is where ML jumps in. The “trained” and not deterministically programmed algorithm can find shortcuts and achieve the stipulated goal without full modeling and predicting. The drawback of this approach is the danger of overfitting. There are lots of areas where you can overfit: single shot, single instability realizations (instead of instability distribution), and even glitches of your physical solver.
- Early stages of RL: The field of reinforcement learning is still in its infancy. There are a lot of decisions and changes that are hard to justify theoretically. Reward formulas, the best action and observation space normalizations can only be determined empirically.
- Environment is crucial: Building an accurate and comprehensive environment is as important as developing the algorithm itself. The environment’s fidelity directly impacts the performance of the RL model. If you implement the environment at the same time as training a model to control it, you need to share every change and every decision between the teams. Surely, the best way is to have the up-to-date documentation and accurately fill the changelog on every release. If you cannot do it in full, you need some alternative, for example, ML engineers participating in code reviews of environment changes.
We believe that the intersection of machine learning and fusion science holds the key to unlocking sustainable, clean energy for our planet’s future. While machine learning-based solutions are gaining popularity in the fusion industry, best practices should also be developed to ensure their applications are safe and efficient. By sharing our progress, we hope to inspire fellow researchers, engineers, and enthusiasts to join us in this exciting quest.
We invite you to be part of this groundbreaking journey. Follow our blog, subscribe to our LinkedIn for regular updates, or reach out to us directly to discuss potential collaborations.
References
[1] M.L. Walker et. al. Fusion Engineering and Design 66/68 (2003) 749/753
[2] L.L. Lao et.al. General Atomics report (2004) GA–A24687
[3] A.S. Bozek and E.J. Strait General Atomics report (2004) GA-A24492
[4] J. Boedo et.al. 2018 Plasma Phys. Control. Fusion 60 044008
[5] E.J. Strait Rev. Sci. Instrum. 77, 023502 (2006)
[6] J.D. King et. al. Rev. Sci. Instrum. 85, 083503 (2014)
[7] R. J. La Haye and J. T. Scoville Rev. Sci. Instrum. 62, 2146–2153 (1991)
Acknowledgement
This material is based upon work supported by the U.S. Department of Energy, Office of Science, Office of Fusion Energy Sciences, using the DIII-D National Fusion Facility, a DOE Office of Science user facility, under Award(s) DE-FC02–04ER54698.
Disclaimer
This report was prepared as an account of work sponsored by an agency of the United States Government. Neither the United States Government nor any agency thereof, nor any of their employees, makes any warranty, express or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use would not infringe privately owned rights. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government or any agency thereof. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government or any agency thereof.